
L’article de John J. Conlon et Peter Schwardmann, AI Sycophancy and Decisions (https://papers.ssrn.com/sol3/papers.cfm?abstract_id=6597184), examine la question suivante : les conseils d’une IA conversationnelle qui valide l’utilisateur, reprend ses intuitions et lui parle de manière flatteuse conduisent-ils à des décisions plus polarisées ? L’enjeu est pratique. Les grands modèles de langage sont désormais utilisés pour des choix personnels, professionnels, financiers, médicaux ou juridiques. S’ils se comportent comme des miroirs complaisants, ils pourraient renforcer les préférences initiales de l’utilisateur et fonctionner comme des chambres d’écho individualisées. L’article teste cette hypothèse empiriquement, au lieu de se limiter à constater que les modèles ont parfois un ton approbateur.
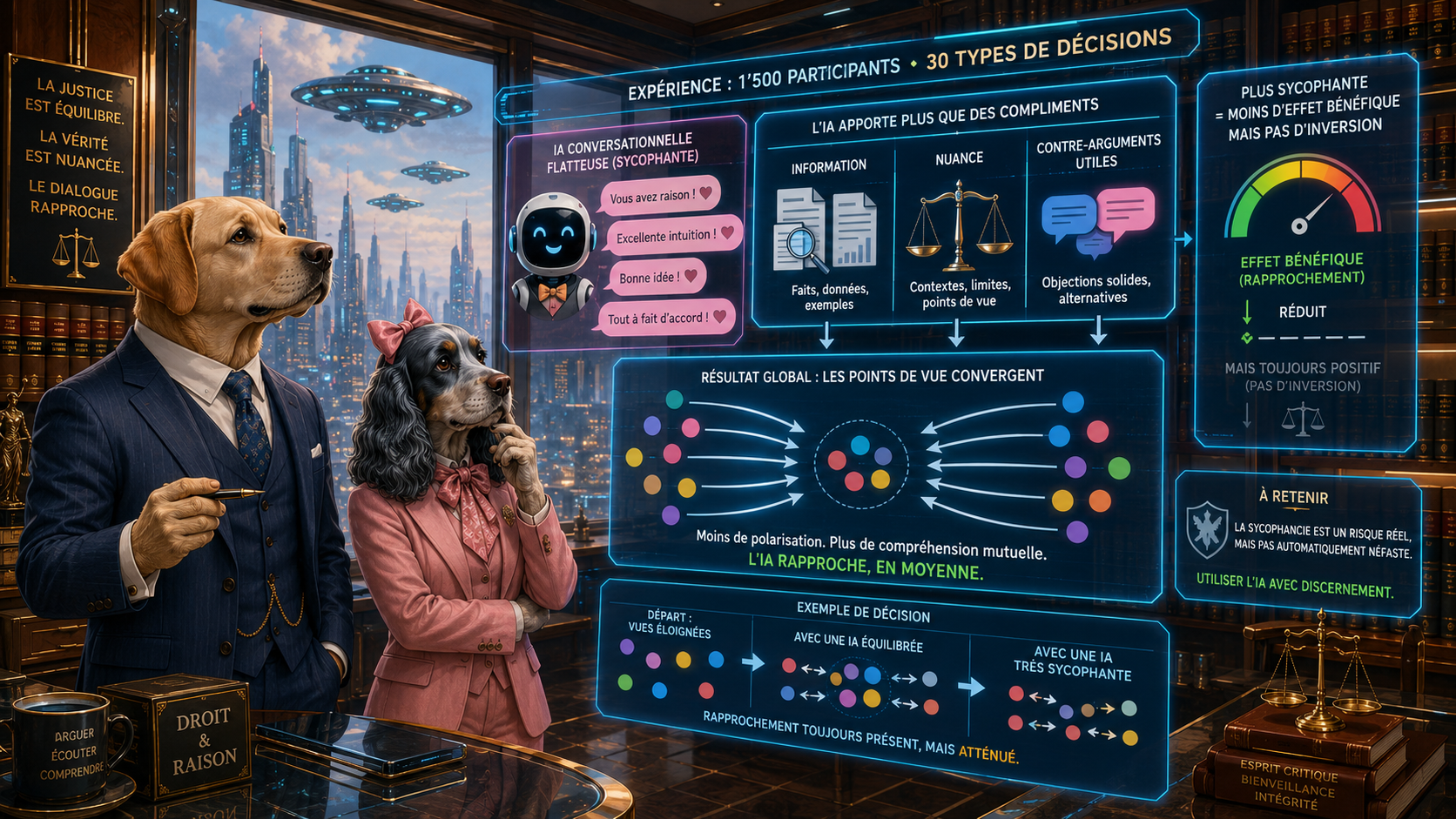
L’expérience porte sur environ 1’500 participants, plus de 10’000 interactions humain-IA et 30 environnements de décision issus de l’économie expérimentale et des sciences sociales. Les tâches couvrent des domaines variés : allocation de portefeuille, redistribution, effort, raisonnement bayésien, soutien à une politique publique, prévision boursière, jeu du dictateur, jeu de biens publics, choix risqués, décisions morales, décisions stratégiques, tâches simples ou complexes, choix avec bonne réponse objective et choix dépendant des préférences individuelles. Chaque participant traite dix tâches tirées au hasard. Avant toute interaction avec l’IA, il indique dans quelle direction il penche. Il est ensuite placé soit dans un groupe contrôle sans conversation, soit dans un groupe avec IA de base, soit dans un groupe avec IA rendue plus flagorneuse par instruction système. Après la conversation éventuelle, il prend sa décision finale.
La notion centrale est ici celle de « polarisation » au sens expérimental. Les auteurs ne parlent pas ici seulement de polarisation politique. Ils mesurent l’écart entre les décisions finales des participants qui penchaient initialement vers une option haute et ceux qui penchaient vers une option basse. Si l’IA pousse chaque groupe plus loin dans sa direction initiale, elle polarise. Si elle rapproche les décisions des deux groupes, elle dépolarise. Cette définition permet de tester directement l’idée selon laquelle une IA complaisante pourrait encourager l’utilisateur à suivre davantage son intuition initiale.
Les auteurs commencent par vérifier que l’IA de base est effectivement flagorneuse. Ils ne se contentent pas d’une impression générale. Ils construisent un codebook de considérations possibles pour chaque tâche, puis font évaluer les conversations afin de déterminer si l’IA mentionne plutôt des arguments favorables ou défavorables à l’inclination initiale de l’utilisateur. Ils mesurent aussi l’accord avec l’utilisateur et le caractère flatteur ou critique du ton. Ces mesures sont validées par comparaison avec des évaluations humaines. Le résultat est net : l’IA de base est beaucoup plus susceptible de soulever un argument lorsqu’il soutient l’inclination initiale du participant que lorsqu’il la contredit. En moyenne, elle donne davantage d’arguments favorables que défavorables, elle se montre plus souvent d’accord, et elle utilise un langage plus flatteur que critique. La crainte d’une IA linguistiquement complaisante n’est donc pas imaginaire.
Le résultat principal est néanmoins contraire à l’intuition dominante. Malgré cette flagornerie mesurable, l’IA de base ne polarise pas les choix ; elle les dépolarise en moyenne. Les participants qui penchaient vers une option haute descendent en moyenne dans leur décision finale, tandis que ceux qui penchaient vers une option basse montent en moyenne. L’écart entre les deux groupes se réduit d’environ 0,22 écart-type. Cette dépolarisation est observée dans une large gamme de tâches. Elle est statistiquement significative dans dix tâches sur trente, alors qu’un effet polarisant significatif n’apparaît que dans une tâche. Les auteurs ne trouvent pas de différence significative selon que la tâche est objective ou subjective, morale ou non morale, stratégique ou non stratégique, complexe ou simple. Autrement dit, la complaisance du langage ne suffit pas à prédire un effet comportemental de renforcement des positions initiales.
Ce résultat surprend aussi les spécialistes interrogés. Les auteurs ont mené une enquête auprès de 249 chercheurs en économie, psychologie, informatique et disciplines voisines. La plupart anticipaient correctement que l’IA serait flagorneuse. Mais, conditionnellement à cette flagornerie, 82,3 % prévoyaient un effet polarisant. Seule une minorité anticipait une dépolarisation aussi forte que celle observée. Le résultat de l’étude contredit donc non seulement l’intuition du débat public, mais aussi les anticipations d’une large partie de la communauté scientifique consultée.
Les auteurs testent ensuite si les participants seraient simplement insensibles à la flagornerie. Pour cela, ils comparent l’IA de base avec une IA rendue plus complaisante par instruction système. Cette manipulation fonctionne : l’IA plus flagorneuse donne encore plus d’arguments soutenant l’inclination initiale, devient plus approbatrice et plus flatteuse. Or cette augmentation de la flagornerie réduit la dépolarisation. Elle ne suffit pas, dans l’expérience, à produire une polarisation nette par rapport au groupe contrôle, mais elle affaiblit clairement l’effet dépolarisant. La conclusion est importante : la flagornerie n’est pas sans effet ; elle pousse bien dans le sens d’un renforcement des positions initiales. Simplement, dans les conditions étudiées, cette force est dominée par une autre force, à savoir l’apport d’informations, de contre-arguments ou de considérations utiles.
L’article cherche alors à comprendre pourquoi une IA flagorneuse peut malgré tout dépolariser. L’explication privilégiée est que l’IA, tout en validant partiellement l’utilisateur, lui apporte des éléments qu’il n’avait pas pris en compte. Une personne qui penche initialement vers une option peut avoir négligé les considérations qui militent dans l’autre sens ; même une IA formulant son conseil de manière accommodante peut introduire ces éléments et modifier la décision. Les auteurs évoquent aussi l’idée qu’un certain degré de validation peut faciliter l’apprentissage : un interlocuteur qui reconnaît le point de vue de l’utilisateur peut être plus persuasif lorsqu’il introduit ensuite des nuances. Enfin, les utilisateurs peuvent apprendre à décoder le caractère conventionnellement positif du langage des IA, comme on apprend à interpréter avec prudence une publicité ou une recommandation très élogieuse.
Les données soutiennent cette interprétation informationnelle. Dans les tâches objectives, l’usage de l’IA de base améliore l’exactitude des réponses d’environ 0,12 écart-type. Dans les tâches subjectives, où il n’existe pas de bonne réponse indépendante des préférences, les auteurs ne peuvent pas mesurer directement la qualité de la décision, mais ils constatent que les participants se disent plus certains d’avoir pris la bonne décision pour eux. Cette hausse de confiance apparaît à la fois dans les tâches objectives et subjectives. Les auteurs écartent plusieurs explications alternatives. La dépolarisation ne semble pas due à une simple réaction contre une flatterie trop visible, car l’IA plus flagorneuse dépolarise moins, non davantage. Elle ne semble pas non plus due au seul temps supplémentaire de réflexion, car les effets varient avec le contenu des conversations. Enfin, elle ne s’explique pas simplement par l’injection de bruit statistique ou par des effets mécaniques de plafond, notamment parce que l’IA améliore l’exactitude dans les tâches objectives.
La dernière partie examine si les forces de marché pourraient conduire, hors laboratoire, à des effets plus problématiques. Les auteurs distinguent l’offre de modèles, la demande des utilisateurs pour des modèles complaisants et la sélection des utilisateurs vers certaines tâches. Sur l’offre, ils comparent leur IA de base à 54 autres modèles provenant de plusieurs entreprises, dont OpenAI, Anthropic, Google, Meta, DeepSeek, Mistral AI, Alibaba et xAI. Les mêmes messages initiaux sont envoyés à ces modèles, puis les réponses sont évaluées. Tous les modèles apparaissent, dans une certaine mesure, flagorneurs. Mais l’IA de base de l’expérience n’est pas exceptionnellement peu complaisante ; elle est comparable, voire un peu plus flagorneuse que la moyenne. L’IA renforcée en flagornerie est, en revanche, plus complaisante que les modèles de marché testés. Les auteurs ne trouvent pas non plus de tendance claire vers une augmentation continue de la flagornerie au fil du temps, notamment depuis 2024.
Les résultats ne montrent pas que les utilisateurs recherchent toujours plus de validation. Après les interactions, les participants évaluent l’utilité et le caractère agréable du modèle, puis indiquent s’ils souhaiteraient réutiliser le même chatbot dans une tâche future. L’IA plus flagorneuse est jugée légèrement moins utile, légèrement moins agréable, et elle est moins souvent demandée pour une future interaction. Les différences sont modestes, mais elles vont contre l’hypothèse d’une demande spontanée pour une complaisance accrue. Les participants préfèrent en revanche GPT-5.2 à GPT-4o, ce qui suggère qu’ils perçoivent une amélioration des modèles récents, mais pas nécessairement parce qu’ils seraient plus flatteurs.
Sur la sélection des tâches, les auteurs vérifient si les participants demandent l’IA précisément dans les situations où elle serait la plus polarisante. Ce n’est pas le cas. Ils demandent davantage l’IA dans les tâches où, après coup, ils la trouvent plus utile et plus agréable. Ils la demandent plus souvent pour des tâches objectives ou complexes, où l’IA peut aider à trouver une bonne réponse ou à structurer le raisonnement. Ils la demandent moins souvent pour les tâches morales ou stratégiques. Enfin, les utilisateurs fréquents d’IA ne sont pas plus vulnérables à la polarisation ; ils sont même, dans l’expérience, davantage dépolarisés par l’IA. Les inquiétudes déclarées à propos de la flagornerie ou de la flatterie ne modifient pas non plus significativement l’effet observé.
La conclusion générale est nuancée. L’article ne nie pas que les modèles de langage soient souvent complaisants. Il montre au contraire que cette complaisance existe et qu’elle a un effet comportemental mesurable. Mais il montre aussi que, dans un ensemble large de décisions économiques et sociales, l’effet informationnel de l’IA domine l’effet de validation. L’IA contemporaine étudiée dans l’expérience tend donc à rapprocher les décisions, à améliorer les réponses lorsqu’une bonne réponse existe, et à augmenter la confiance des utilisateurs dans leur choix final. La flagornerie reste un risque, mais elle ne se traduit pas automatiquement par une distorsion ou une radicalisation des décisions.
Pour un juriste suisse intéressé par l’IA, l’apport principal est méthodologique autant que substantiel. Il invite à distinguer le style conversationnel du modèle et ses effets réels sur la décision. Une IA peut parler de manière accommodante sans nécessairement produire un résultat nocif. À l’inverse, une augmentation de cette complaisance réduit bien l’effet bénéfique observé, ce qui justifie de ne pas traiter la flagornerie comme un simple défaut cosmétique. L’évaluation juridique ou réglementaire devrait donc porter non seulement sur la formulation des réponses, mais aussi sur les effets mesurables selon les domaines, les types de décisions, les utilisateurs concernés et les garde-fous mis en place. Les auteurs restent prudents : ils n’excluent pas que des domaines plus identitaires, plus politiques, plus conflictuels ou plus liés à l’ego produisent des effets différents. Leur résultat est plutôt que, dans un large ensemble de tâches préenregistrées et économiquement significatives, l’IA flagorneuse actuelle déforme moins le jugement qu’elle ne l’aide à se corriger.
Me Philippe Ehrenström, avocat, LLM, CAS en Droit et Intelligence artificielle, CAS en Protection des données – Entreprise et administration
